ColorRL for E2E Instance Segmentation: A Quick Overview
The paper “ColorRL: Reinforced Coloring for End-to-End Instance Segmentation” proposes an RL-based instance segmentation algorithm. Unlike the previous post on interactive segmentation, this one focuses on training a model for segmenting instances in a single pass. Specifically, the algorithm uses reinforcement learning to separate a single segmentation into individual instances.
The ColorRL Model
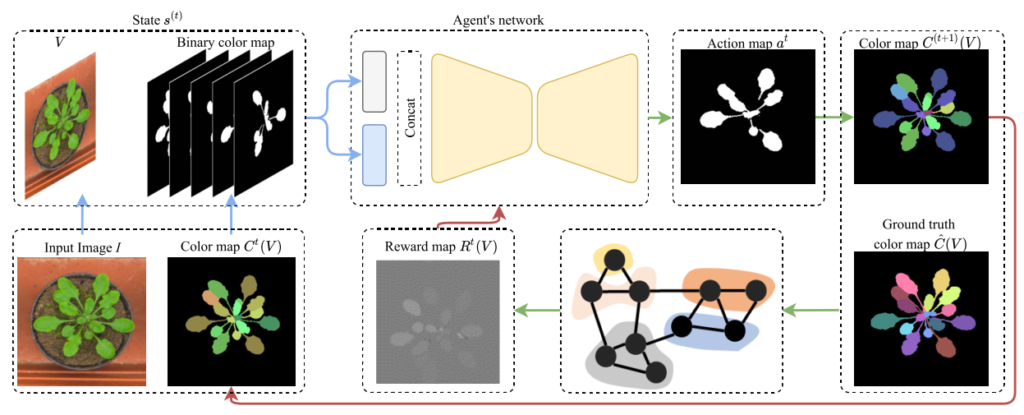 ColorRL Model Architecture
ColorRL Model Architecture
The architecture of the proposed model is as above. Let’s discuss the main parts of the architecture.
State
The state consists of 2 parts:
-
Input image: An array of size HxWxCH
-
Binary color map
-
This is an array of size HxWxT, containing binary values (0 or 1)
-
H = Height, W = Width, T = Coloring steps (T steps can encode up to $2^T$ distinct colors, i.e., instance labels)
-
It is initialized to be zeros.
-
Note: Since the array contains binary values, it can also be represented as an array of size HxW with each element having a maximum value of $2^T - 1$.
-
Accordingly, the state is an array of size HxWx(CH+T).
ColorRL Agent
First, the image and the binary color map are processed using a neural network. Next, the concatenated results pass through the agent’s encoder-decoder network.
The agent, in this case, is actually a collection of sub-agents, where each agent is in charge of a single pixel of the image. Here, every agent looks at the neighboring pixels in the input state and predicts an action. These pixel-level agents are trained using the Asynchronous Advantage Actor-Critic (A3C) algorithm, following the approach of PixelRL.
Action
The action denotes the value of the tth binary digit (bit) of the respective pixel’s color. Accordingly, the combination of all these binary pixel values forms a binary map that can cover several instances at once — after all T steps, pixels that ended up with the same T-bit color form a single instance.
Next, this binary map will now take the place of the tth frame of the binary color map. Additionally, it is also used to calculate the reward.
Reward
Graph Formulation
The authors approach this by formulating the binary color maps into graphs:
-
Vertices: Each pixel is a vertex in the graph.
-
Edges: Two pixels are connected by an edge if they are adjacent to each other.
-
Pixels that belong to the same instance (have the same value) are grouped into partitions.
Accordingly, you can think of the outcome of each action as one of the following:
- Split: Two connected pixels of the same partition are separated into different partitions.
- In other words, two pixels that were previously of the same instance are now in separate instances.
- Merge: Two connected pixels of different partitions are combined into the same partition.
- In other words, two pixels that were previously of different instances are now in the same instance.
This process is visualized and described in the following image from the paper.
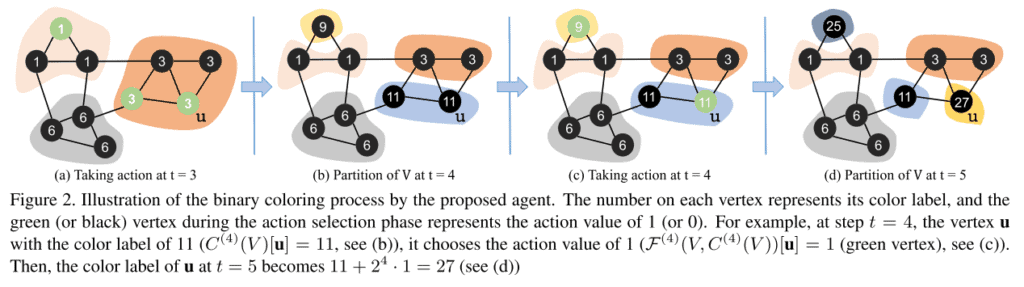 Binary coloring process in ColorRL
Binary coloring process in ColorRL
Reward Function
Simply put, the reward function checks if a certain split/merge fixed a previously incorrect partition or broke a previously correct partition. In other words:
- Merging Reward: If two pixels of separate instances are combined,
-
If the two pixels are in the same partition in the ground truth graph => Positive reward
-
If not => Negative reward
-
- Splitting Reward: If two pixels of the same instance were separated,
-
If the two pixels are in the same partition in the ground truth graph => Negative reward
-
If not => Positive reward
-
In addition to the above two rewards, the authors propose also rewarding the agent when it predicts a foreground pixel as foreground or a background pixel as background. The following reward function describes this Background-Foreground Reward:
 The background-foreground reward function from the ColorRL paper
The background-foreground reward function from the ColorRL paper
Finally, the sum of all three of these rewards (weighted by some coefficients) forms the final reward function.
Final Thoughts
That’s it! I hope this was helpful and of course, let me know if you would like any clarification about any part. Feel free to check out the rest of my blog and see if anything else seems interesting.