Reinforcement Cutting-Agent Learning for VOS - A Quick Overview
In the previous post, I discussed a technique that uses Reinforcement Learning (RL) for instance segmentation. In this post, let’s go over a paper called “Reinforcement Cutting-Agent Learning for Video Object Segmentation” by Han et al. which, as the name suggests, proposes a technique that uses RL for Video Object Segmentation (VOS).
- The Cutting-agent’s Model
- Cutting-execution Network
- The Reward for the Cutting-agent
- Examples
- Summary
- Final Thoughts
The Cutting-agent’s Model
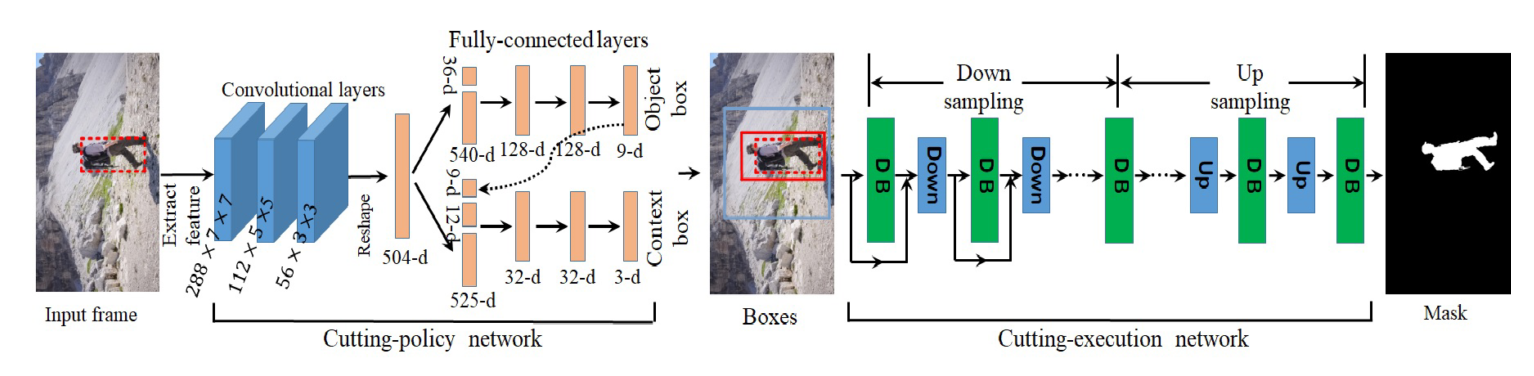 Cutting-Agent Model Architecture
Cutting-Agent Model Architecture
Inputs: The video (a sequence of frames) and the bounding box for the object in the first frame
Outputs: A set of segmentation masks for the object, each of which corresponds to a frame in the input video.
The proposed model has 2 main parts:
-
Cutting-policy network (CPN)
-
Cutting-execution network (CEN)
Cutting-policy Network
The CPN accepts a frame (image) as input and outputs 2 vectors (actions):
-
Object search action
-
Context embedding action
Object Search Action
 Object searching action list
Object searching action list
The purpose of the object search action is to adjust the object’s bounding box. As shown in the above image, it can be one of 9 different actions:
-
Translation: Move the bounding box to the right, down, left, or up.
-
Scale: Scale the box up or down, horizontally or vertically.
-
Stop: Stop iterating because the box has been identified.
Accordingly, it is represented by a 9-dimensional one-hot encoded vector.
Context Embedding Action
 Context embedding action list
Context embedding action list
The context embedding action generates a second box that’s larger than the object’s bounding box. This new bounding box indicates to the model what the surrounding looks like.
The action is a scalar value:
-
Small: 0.2 by default
-
Medium: 0.4 by default
-
Large: 0.6 by default
Accordingly, it is represented by a 3-dimensional one-hot encoded vector.
Choosing the actions
As shown in the model architecture, the two actions are generated by two branches of fully-connected layers.
In addition to the encoded image, each branch also accepts a history of the actions generated during the current frame. The authors state that maintaining the history of 4 iterations results in the best performance. Accordingly,
-
the history of the object search action is 36-dimensional (9x4) and
-
the history of the context embedding action is 12-dimensional (3x4)
Additionally, the context branch also accepts the object search action as part of its input.
All these points are clearly mentioned in the diagram.
Context Box Generation
The model generates the context box as follows:
-
Say the value is called B.
-
The distances from the edges of the frame to each of the 4 edges of the object bounding box are calculated.
-
Each of the distances is multiplied by B and a new edge is formed at that distance from the object bounding box’s edge.
The boxes are then passed into the CEN.
Cutting-execution Network
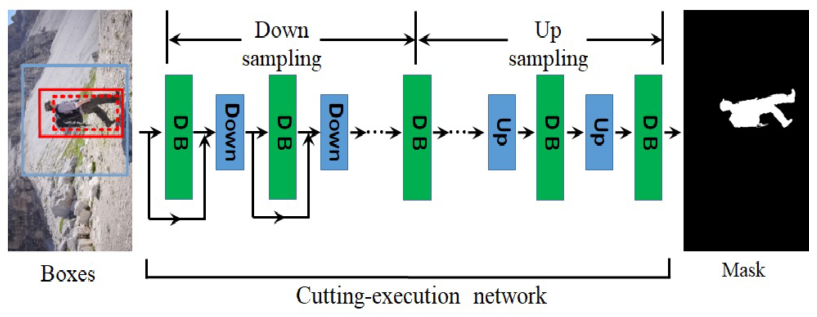 The input to the CEN is a 4-channel input, where the 4th channel contains the context box (a matrix of zeros with ones inside the box).
The input to the CEN is a 4-channel input, where the 4th channel contains the context box (a matrix of zeros with ones inside the box).
The architecture of the CEN works similarly to the FC-DenseNet model. Take a look at this article for a better understanding of how the model works.
Accordingly, the output of the CEN is a segmentation mask.
Finally, the boundaries of the object in the mask are used to define the bounding box for the next iteration.
The Reward for the Cutting-agent
The reward for the model is as follows:
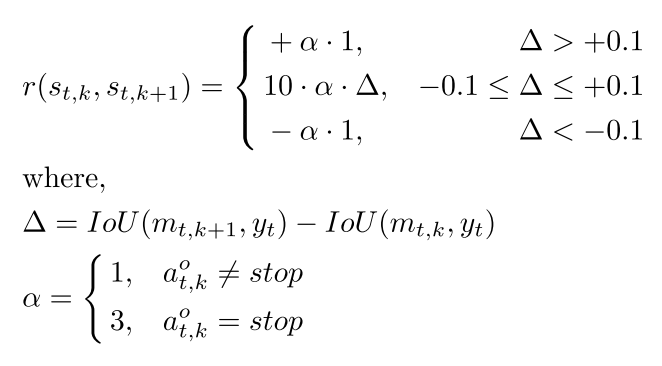 The reward function
The reward function
In summary, the reward is the improvement in the Intersection over Union (IoU) compared to the previous step.
Few things to note
-
As seen by the equation, the reward is capped between -alpha and +alpha. As a result, it is easier for the agent to understand the impact of a certain action.
-
Alpha is equal to 3 when the action is “stop”. This is to make sure that the action that led to the final result makes a larger impact on training.
Examples
The following is a pair of examples that the authors present.
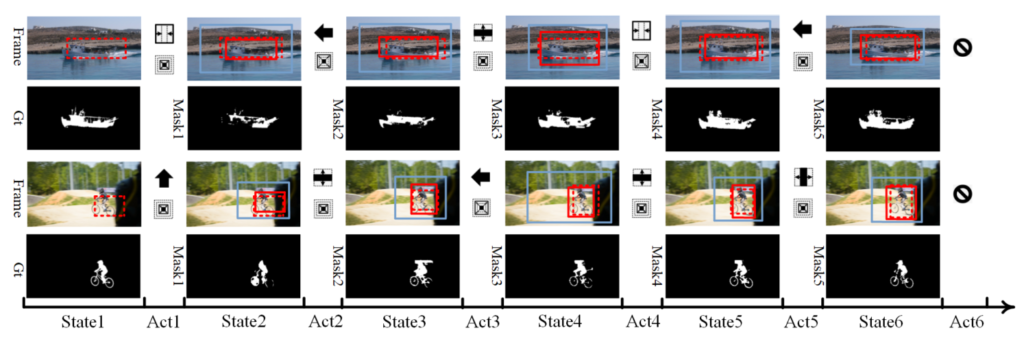 Two examples of a single iteration of the algorithm
Two examples of a single iteration of the algorithm
Note how each action affects the input box (dotted red box) to generate the object box (solid red box) and the context box (solid blue box). Also, note how the sequence ends with the prediction of the “stop” object action.
Summary
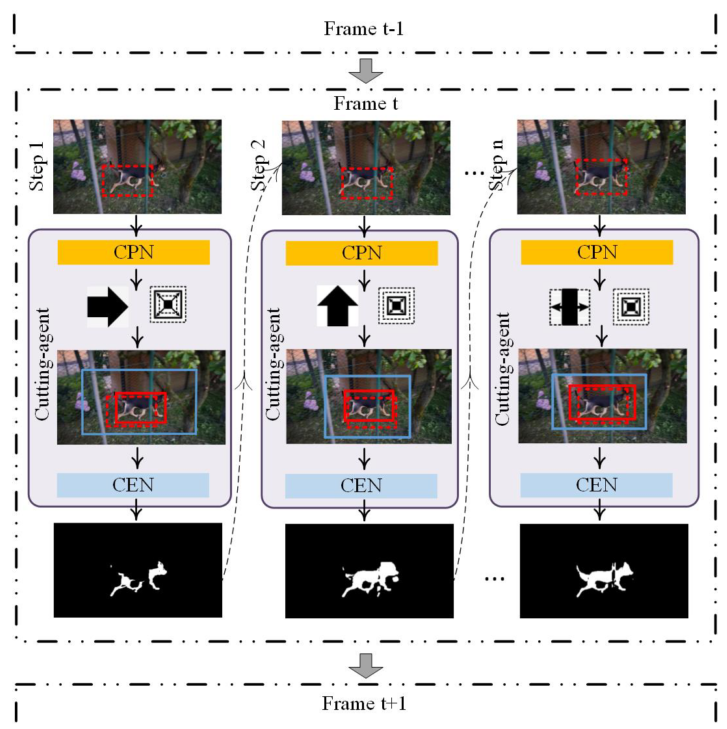 Summary of the proposed approach as given in the paper
Summary of the proposed approach as given in the paper
-
The video sequence and the bounding box of the object in the first frame are the inputs to the algorithm.
- The CPN uses these to predict two actions:
-
Action 1 moves and scales the input bounding box (object box)
-
Action 2 generates a bounding box larger than the first (context box)
-
-
Next, the CEN uses the boxes and the frame to generate a segmentation mask.
-
During training, the IoU of this segmentation mask against the ground truth mask dictates the reward for the agent.
- Finally, the segmentation mask is fed back into the CPN and the process repeats until the CPN predicts the “stop” action.
Final Thoughts
I hope you found this useful. I didn’t go into too much detail about the training process because it may unnecessarily bloat the article. If you would like any clarifications, feel free to reach out.
Thanks for reading. If you’d like to see more similar paper explanations, head on over to the Explained page of my blog.