SeedNet for Interactive Segmentation - A Quick Overview
SeedNet is a model that uses Reinforcement Learning (RL) for interactive segmentation. Interactive segmentation is a method of segmenting images using user input. Here, the user iteratively adds points (a.k.a “seeds”) to the image, indicating whether the given point is a part of the object or a part of the background. SeedNet uses RL to predict new seed locations, which leads to more robust segmentation.
 SeedNet Process
SeedNet Process
SeedNet Architecture
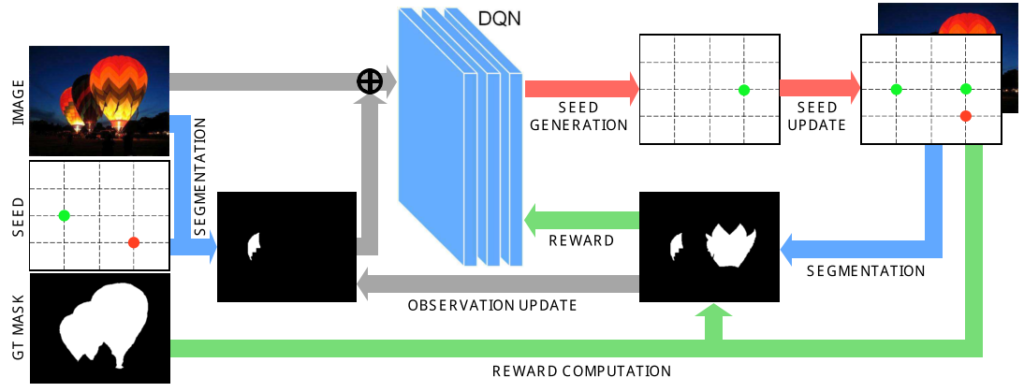 SeedNet model architecture
SeedNet model architecture
Let’s walk through the architecture, section by section.
1. Inputs
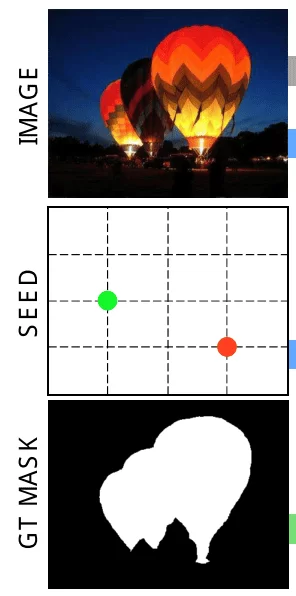 Inputs of SeedNet
Inputs of SeedNet
-
The image to be segmented
- The initial set of seeds
-
The user provides a pair of initial seeds: a point on the object (foreground) and a point on the background.
-
The new seeds generated by the agent, however, are placed on a sparse 20x20 grid. This is because the number of possible actions would be too high if the agent could pick pixel locations instead.
-
- Additionally, during training: the ground truth mask (GT Mask)
2. Segmentation
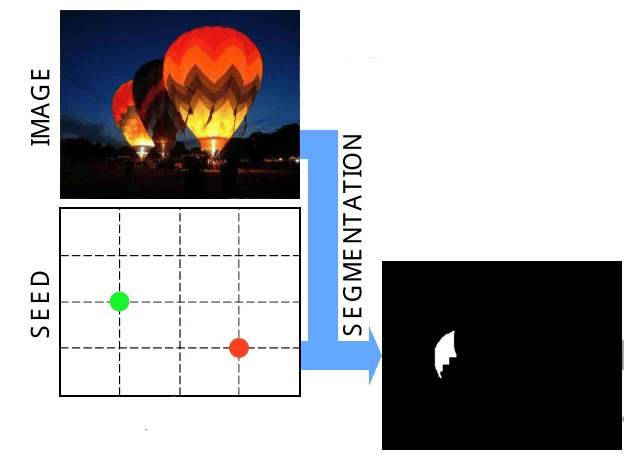 Segmentation section of SeedNet
Segmentation section of SeedNet
Next, the positions of each seed, given by the user, are used to perform segmentation on the image. The output of this is a binary mask.
In the above image, the green dot represents a position that’s considered to be the foreground, while the red dot represents a point in the background. These 2 points are combined with an existing interactive segmentation algorithm to obtain the binary mask. In the paper, they use an algorithm called Random Walk (RW).
3. Reinforcement Learning in SeedNet
RL Formulation
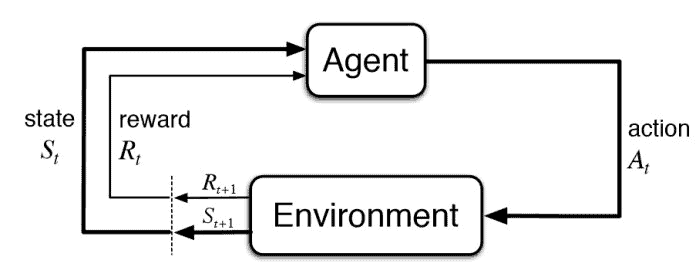 Reinforcement Learning Formulation
Reinforcement Learning Formulation
Before moving on to the next step, let’s take a quick look at how RL problems are usually formulated. A typical RL problem has 5 main components:
-
Agent
-
Environment
-
State
-
Action
-
Rewards
Here, the following workflow occurs:
-
The agent performs an action.
-
The environment provides a reward to the agent based on the action.
-
The agent accepts the reward and reads the new state from the environment.
-
Based on the reward and the new state, the agent performs a new action.
Deep Q-Networks
The main reinforcement learning model in this algorithm is a Deep Q-Network (DQN). A DQN is essentially an architecture where a neural network predicts the action values (Q-values) for a given state.
To get a better understanding of q-learning, take a look at this great article. It’s a fairly long post, but it has everything you need to understand about Q-learning, from the ground up.
Training
You can think of the DQN as the agent of the system and the rest of the program as the environment.
-
The state, which is given as input to the DQN, is defined by a concatenation of the original image and the currently generated segmentation mask.
-
The action is a position on the 20x20 grid at which the new seed is suggested to be placed, along with the label (foreground or background) of that seed.
-
The combination of all the seeds is used to generate a segmentation mask via an interactive segmentation algorithm.
-
Accordingly, this new segmentation mask would be the next state.
-
During training, the reward is calculated by comparing the segmentation mask against the ground truth mask. The reward function will be discussed further in the next section.
-
The DQN uses the reward to update its weights.
-
Note: We don’t have to calculate the reward during inference.
Reward function
The authors experimented with several types of reward functions:
-
The first reward function calculates the difference in the intersection over union (IoU) score between the new and previous segmentation masks
-
Secondly, they tried a reward function that uses the exponentiated IoU of the new segmentation mask.
-
Finally, what worked best for them was as follows:
- They divide each image into 4 regions:
-
strong foreground (SF): closer to the center of the foreground
-
weak foreground (WF): far from the center of the foreground, but still in the foreground
-
strong background (SB): closer to the center of the background
-
weak background (WB): far from the center of the background, but still in the background
-
- Next, they calculate the reward based on where the new point falls on the image.
- They divide each image into 4 regions:
The final reward function was as follows:
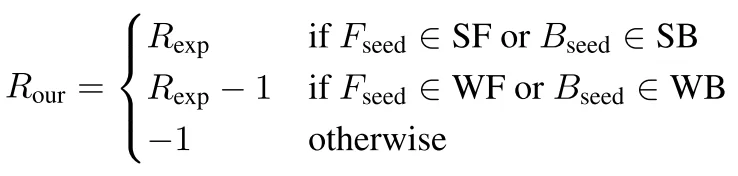 SeedNet Reward function
SeedNet Reward function
where Fseed means foreground seed, Bseed means background seed, and Rexp is the reward function of the second approach (the next image).
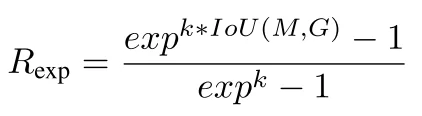 Exponential reward function of SeedNet
Exponential reward function of SeedNet
Final Thoughts
Feel free to reach out if you have any doubts regarding this explanation. If you want to see more paper explanations, check out the Explained page on my blog.